The environment
LunarLander-v3 is a physics simulation where a spacecraft starts mid-air above a lunar surface. Two yellow flags mark the landing pad. The goal is to land between them, upright, without crashing. The agent controls four thrusters: do nothing, fire left engine, fire main engine, fire right engine.
Every timestep, the environment returns 8 numbers describing the lander's current state — and a reward signal telling the agent how well it's doing. There are no instructions. Just experience.
env = gym.make("LunarLander-v3", render_mode="rgb_array") state, info = env.reset() # State space: 8 continuous values # Box([-2.5 -2.5 -10. -10. -6.28 -10. -0. -0.], # [ 2.5 2.5 10. 10. 6.28 10. 1. 1.], shape=(8,)) # Action space: 4 discrete actions # Discrete(4) — do nothing / left engine / main engine / right engine print("State space:", env.observation_space) # Box (8,) print("Action space:", env.action_space) # Discrete(4)
The 8 state values are: x position, y position, x velocity, y velocity, angle, angular velocity, and two booleans for whether the left and right legs are touching the ground. That's everything the agent gets to work with.
Why Actor-Critic?
You could use a simpler algorithm — just tracking which actions led to good outcomes and repeating them. But estimates based on full episode rewards are noisy. A single run can go well or badly by chance, and you'd update your policy based on that noise.
The Critic solves this by estimating how good each state is in real time, not just at the end of an episode. It gives the Actor a much more stable, moment-by-moment signal to learn from. Think of it like having a coach watching in real time rather than only giving feedback at the final whistle.
The two neural networks
Both networks share the same 8-value input. They diverge completely in what they output.
class Actor(nn.Module): def __init__(self, state_dim, action_dim): self.fc1 = nn.Linear(state_dim, 128) # 8 inputs → 128 neurons self.fc2 = nn.Linear(128, 64) # 128 → 64 self.fc3 = nn.Linear(64, action_dim) # 64 → 4 action probabilities def forward(self, state): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(x)) return torch.softmax(self.fc3(x), dim=-1) # probabilities sum to 1
class Critic(nn.Module): def __init__(self, state_dim): self.fc1 = nn.Linear(state_dim, 128) self.fc2 = nn.Linear(128, 64) self.fc3 = nn.Linear(64, 1) # single scalar: V(s) def forward(self, state): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(x)) return self.fc3(x) # no activation — raw value, can be negative
What the networks output before any training
Before training starts, both networks are randomly initialised. Here's what the very first forward pass looks like — before the agent has learned anything:
state = torch.tensor(state, dtype=torch.float32) action_probs = actor(state) state_value = critic(state) # Output: Action probabilities: tensor([0.2508, 0.2384, 0.2497, 0.2611]) State value: tensor([-0.1508])
Notice how the action probabilities are almost perfectly equal — 25% each. That's a randomly initialised network with no preference at all. And the state value is −0.15, essentially saying "I have no idea how good this is." This is the starting point. Everything learned from here is through trial and error.
The full training loop
Every timestep follows the same five-step cycle. Here's the actual code:
rewards_history = [] for episode in range(num_episodes): state, info = env.reset() state = torch.tensor(state, dtype=torch.float32) episode_rewards = 0 for step in range(max_steps_per_episode): # Step 1: Actor picks an action probabilistically action_probs = actor(state) action_dist = torch.distributions.Categorical(action_probs) action = action_dist.sample() # Step 2: Execute in environment next_state, reward, done, truncated, info = env.step(action.item()) next_state = torch.tensor(next_state, dtype=torch.float32) episode_rewards += reward # Step 3: Compute advantage — was this better or worse than expected? value = critic(state) next_value = critic(next_state) if not done else torch.tensor(0.0) target = reward + gamma * next_value.item() advantage = target - value.item() # TD error # Step 4: Update Actor — do more of what worked actor_loss = -action_dist.log_prob(action) * advantage actor_optimizer.zero_grad() actor_loss.backward() actor_optimizer.step() # Step 5: Update Critic — get better at predicting state values target_tensor = torch.tensor(target, dtype=torch.float32) critic_loss = value_loss_fn(value, target_tensor) critic_optimizer.zero_grad() critic_loss.backward() critic_optimizer.step() state = next_state if done: break rewards_history.append(episode_rewards)
Hyperparameters
The Critic's learning rate (0.005) is 5× higher than the Actor's (0.001). This is intentional — the Critic needs to develop a useful baseline before the Actor can meaningfully improve against it. If they learn at the same rate, neither gets a stable signal.
The real training log — every 10 episodes
This is the actual output from running the notebook. You can see the full story of the agent learning, failing, discovering something, losing it again, then eventually converging:
# Early chaos — crashing on almost every attempt Episode 0, Reward: -232.47 Episode 10, Reward: -1293.77 # worst episode Episode 20, Reward: -407.11 Episode 50, Reward: -576.70 Episode 90, Reward: -1021.64 # Still struggling but stabilising around -500 Episode 100, Reward: -716.49 Episode 200, Reward: -497.55 # First hints of learning — approaching zero Episode 220, Reward: -274.53 Episode 230, Reward: -21.30 # nearly zero for the first time Episode 330, Reward: +8.58 # first positive episode! # First successful landing Episode 360, Reward: +265.58 # breakthrough moment # Convergence — mostly positive, occasional relapses Episode 430, Reward: +241.96 Episode 440, Reward: +299.77 Episode 450, Reward: +284.86 Episode 530, Reward: +284.78 Episode 640, Reward: +259.95 Episode 770, Reward: +249.20 Episode 850, Reward: +250.56 Episode 890, Reward: +276.66 Episode 990, Reward: +225.91
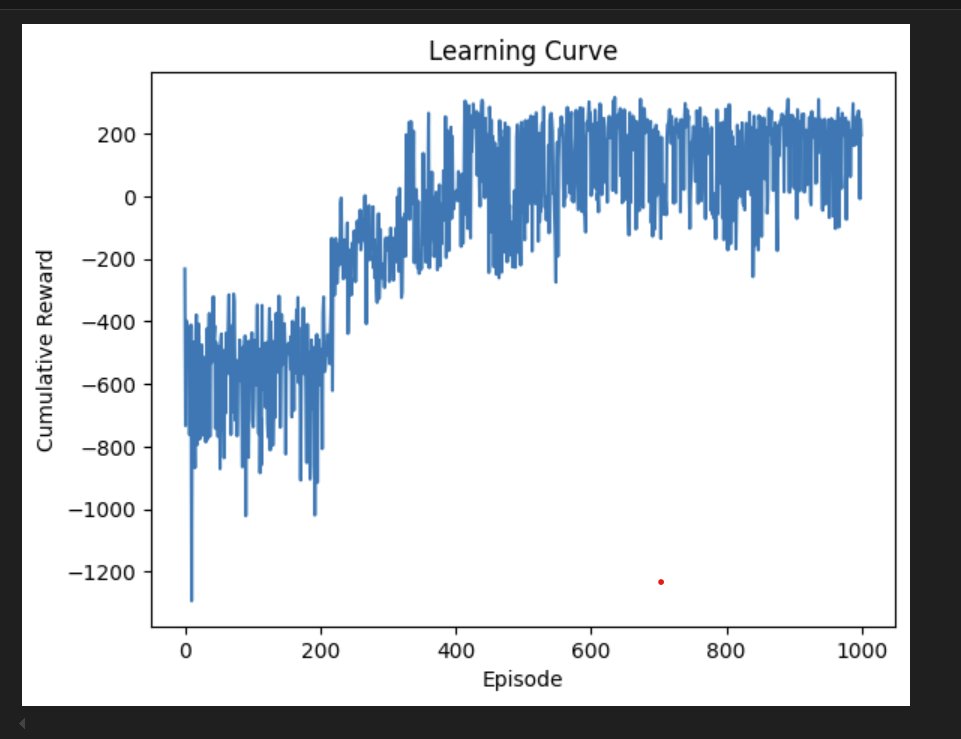
The learning curve
Episode 10 was the worst — reward of −1,293. Episode 330 was the first to go positive. Episode 360 hit +265, which was the first clear successful landing. After that, rewards clustered above zero with occasional relapses, converging to an average of +187.27.
Evaluation — how good is it really?
During evaluation, the Actor doesn't sample probabilistically — it just picks the action with the highest probability (greedy). This removes exploration noise and shows the true learned policy.
def evaluate_model(actor, num_episodes=10): for _ in range(num_episodes): # During eval: pick the BEST action, no sampling action = torch.argmax(action_probs).item() evaluation_rewards = evaluate_model(actor) print(f"Average Reward Over Evaluation: {np.mean(evaluation_rewards)}") # Output: Average Reward Over Evaluation: 187.27428490096685
random_rewards = random_policy(env) print(f"Average Reward for Random Policy: {np.mean(random_rewards)}") # Output: Average Reward for Random Policy: -219.30102964861507
Random policy: −219.30. Trained Actor-Critic: +187.27. That's a gap of over 406 points — the entire difference between crashing every single time and reliably sticking the landing. The algorithm genuinely learned to fly.
What was actually hard
- Hyperparameter tuning — the learning rate ratio between Actor and Critic matters enormously. If the Critic learns too slowly, the Actor gets noisy signals. If too fast, it destabilises everything. Getting the 1:5 ratio right took multiple runs.
- Overfitting behaviour — you can see the occasional large negative spikes even at episode 800+ in the learning curve. The agent sometimes locked into specific action sequences that worked in certain conditions but didn't generalise. That's the exploration vs exploitation tension playing out in real time.
- MSE loss shape mismatch — the notebook threw a
UserWarningabout target size(torch.Size([]))vs input size(torch.Size([1])). This is a known broadcasting issue when passing a scalar tensor to MSELoss. It still ran correctly but ideally should be fixed with.unsqueeze(0). - Version deprecation — LunarLander-v2 was deprecated mid-project, requiring migration to v3.
What I'd try next
- Fix the MSE shape warning —
target_value_tensor.unsqueeze(0)ensures the shapes match properly - Entropy regularisation — add a bonus term to keep the Actor from collapsing to a deterministic policy too early, which would explain some of the late-training relapses
- Longer training — the curve hasn't fully plateaued at 1,000 episodes; 3,000–5,000 would likely push average reward above 220
- Generalisation testing — run the trained agent on randomised starting conditions to measure robustness
- Image-based variant — use the RGB render output as input instead of the 8 state values, requiring a CNN front-end
Team
- Shayam Kishore Kotapati — 200600387
- Maria Namitha Nelson — 200601260
- Vishnu Sreekumaran Nair — 200557136